
Since ChatGPT turned the world of AI research upside down at the end of 2022, dozens of new and supposedly powerful AI models have been released every day. When the Chinese research lab DeepSeek unveiled its latest model R1 on January 20, it initially caused little stir.
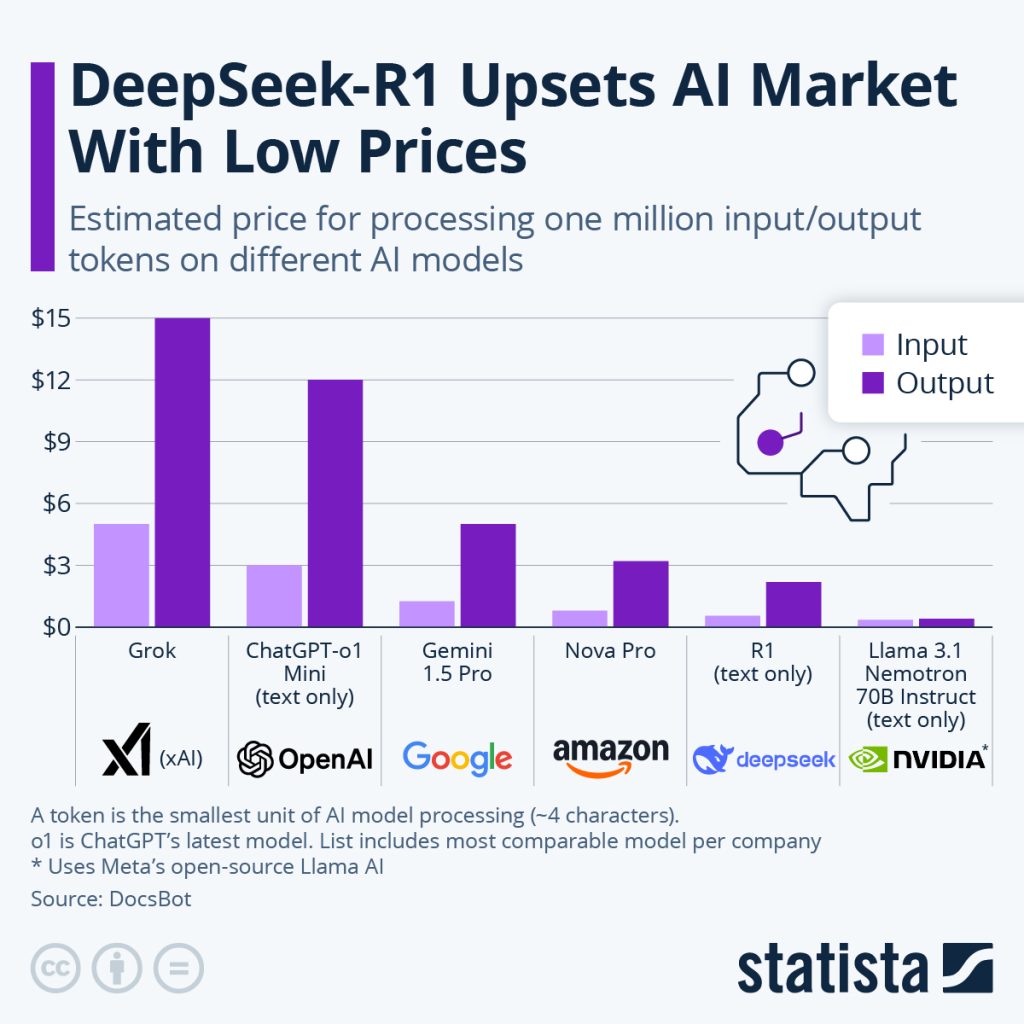
The fact that the company claimed that R1 would have the same performance as OpenAI’s o1 (currently the best commercially available model) but at the same time be 97% cheaper, initially caused skepticism among experts. Within a few days, skepticism gave way to astonishment and then panic. R1 seemed to deliver what it promised – and it’s free. This means that many premises of the current AI boom need to be fundamentally questioned.
Note: The companies listed in this article have been selected as examples and do not constitute an investment recommendation.
Premise 1: better models are more expensive
Large language models (LLMs for short) are prediction models based on neural networks whose main task is to provide the most likely subsequent word components (so-called tokens) for a given input. So if I give the model the input “When the sun is shining”, the probable outputs would be “is”, “the”, “sky” and “blue” plus a so-called end token <end>, which tells the model that no further output should follow. How and in what order the outputs are generated is determined by the so-called parameters of the model, which must be “trained” when the model is created.
Put simply, a parameter could read: “If the previous token is <that>, then the next token is <is> with a probability of 78%”. However, since human language offers almost infinite possible combinations of words and units of interpretation, even a million of these “if-then” rules are not enough to form a readable and coherent sentence.
Useful models start from a parameter density of approx. one billion. Roughly speaking, the more parameters a model has, the better it works. A 7 billion parameter model like Meta Llama 3.3 (small) can easily be installed on a standard laptop and provides good answers to common questions (Wikipedia knowledge, for example). At the other end of the performance spectrum are models such as OpenAI GPT4o with an estimated parameter density of over a trillion. This model can easily answer questions about specific areas of knowledge such as medicine or engineering, or write maudlin poems in Armenian.
Basically, the more parameters the target model should have, the more computing operations need to be performed when training these models. The basic unit for arithmetic operations is called FLOPS (short for floating point operations per second). The calculation task 1+1 corresponds to one FLOP. Although in our example GPT4o is 170 times as capable as the small Llama model, it required 230 times as many computing resources in training. In short, the computing costs increase more steeply than the capability of the model – at least that’s what we thought until last week.
DeepSeek puts pressure on previous AI models
With so many events, one thing must not be forgotten: Just over 2 years have passed between the training of GPT3, the first model many of us learned about ChatGPT with in late 2022 and which was trained for USD 10 million, and President Trump’s announcement of USD 500 billion for the further development of AI models.
During this time, large tech companies, private equity investors and venture capitalists have invested staggering sums in the AI sector . A total of over USD 300 billion is expected to be invested by 2024. The news that the Chinese AI research team DeepSeek has trained a model with a cost base of just over USD 5 million that can compete with the top models of the US tech giants, which have invested hundreds of times that amount, came in the midst of this environment.
In order to limit the competitiveness of Chinese AI research, the Biden government had already imposed export bans on Nvidia’s latest generation of chips. Of course, it can be assumed that these restrictions were partially circumvented via imports from third countries, similar to the sanctions against Russia. The fact is, however, that these restrictions prompted Chinese researchers to look for resource-saving methods to overcome this handicap.
The result of these efforts are the DeepSeek V3, R1 and Janus models, which each represent different use cases. Unfortunately for the US tech giants, the Chinese researchers have not only published their methods, but have also made their models publicly available. Put simply, any user with enough computing power can now use them to create their own ChatGPT.
Required computing power could plummet
It remains to be seen how the US competition will react immediately to this development. In the medium to long term, however, it is inconceivable that these groundbreaking methodological innovations will not be adopted by other research teams. As a result, the computing power required across the entire industry is likely to plummet. The question arises as to why the models do not simply become larger now that resources can be used more efficiently.
A car that only needs 3l/100km goes much further than one with a consumption of 10l/100km, doesn’t it? Unfortunately for the entire semiconductor industry, there has been growing evidence in recent months that the performance of the best LLM models has reached a ceiling and that even with an increasing number of parameters, it is not possible to achieve significantly better performance.
Premise 2: Open source is 2nd league
In software distribution, a basic distinction is made between closed source and open source. Closed source is a black box for the user, for which only the software manufacturer has the key and can therefore control very precisely who uses the software and for what purpose. Open source software is an open book and freely available. Every user is free to use it for private or commercial purposes without restrictions.
These two variants also exist for AI models, with the closed variant being considered the premium version until a week ago. Although the Facebook parent company Meta makes its models available to everyone, they always lag a few steps behind the commercial models in common benchmarks. Until now, anyone who wanted or needed the best performance had to open their wallet. DeepSeek has put an end to this. Its open source models play in the premier league and are still available to everyone.
How could this affect chip manufacturers?
This has put an end overnight to countless AI start-ups, which of course primarily have to build their own models with closed-source distribution in order to be able to generate revenue for their investors at some point. One consequence of this is that many venture investments in this area will have to be written off in the medium term. As private equity funds are generally able to grant themselves more flexibility in terms of amortization and reporting, the negative consequences of this development will take several years to be felt by investors.
On the other hand, there are concerns that faltering or pivoting start-ups will sell graphics chips on a large scale, which they have purchased at great expense with investors’ money over the past few years. This glut on the secondary market could cause demand on the primary market to falter. An Nvidia H100 chip from 2022 cost USD 30,000 at launch and therefore USD 500/TFLOP. The B100 chip announced for 2025 is listed at USD 40,000 and therefore costs USD 300/TFLOP. If the used price for the H100 chips were to fall below the USD 18,000 mark and a significant quantity were to become available, unit economics (sales and costs on the basis of a single unit, e.g. a product or service) would probably start to exert strong pressure on Nvidia’s sales.
A counter-argument could be that the efficient open source architecture means that many companies could decide to host their own LLMs, whereas in the past they would have resorted to the cloud-based solutions of hyperscalers Amazon, Microsoft and Google. For example, it would not have been realistic for a company like Erste Group to provision its own computing cluster for an LLM. To host Llama 3.3 Large, you would need around 200 A100 chips. In addition to the 6 million USD acquisition costs, energy and infrastructure costs would pile up, which would put an end to any discussion about self-hosting. DeepSeek R1 would not only be the better model, but would also get by with 5-10 A100 chips. At 200,000 USD acquisition costs, one or two medium-sized companies might be tempted to start a project to try out the new technology themselves and at the same time retain control over the data used.
From Nvidia’s point of view, this move would only be welcome, as it would spread the dependency on a few large customers with corresponding negotiating power across many smaller and less negotiating customers.
Premise 3: AI models are a software product
Until recently, the business case of most AI start-ups was probably as follows: “We train a model with investor money and then earn money from consumers via a subscription model and from companies with an API model”. This was based on the assumption that an AI model is a product similar to software such as Office or Photoshop and that if your own model is good enough, you will be able to retain customers. Of course, the US tech giants were nibbling on the sidelines, demanding their payment for the cost-efficient hosting of the API models. DeepSeek has also put an end to these assumptions. Within days, countless OpenAI customers canceled their subscriptions and switched to the free alternative from China. Customer loyalty, what is that?
Note: Prognoses are not a reliable indicator of future performance.
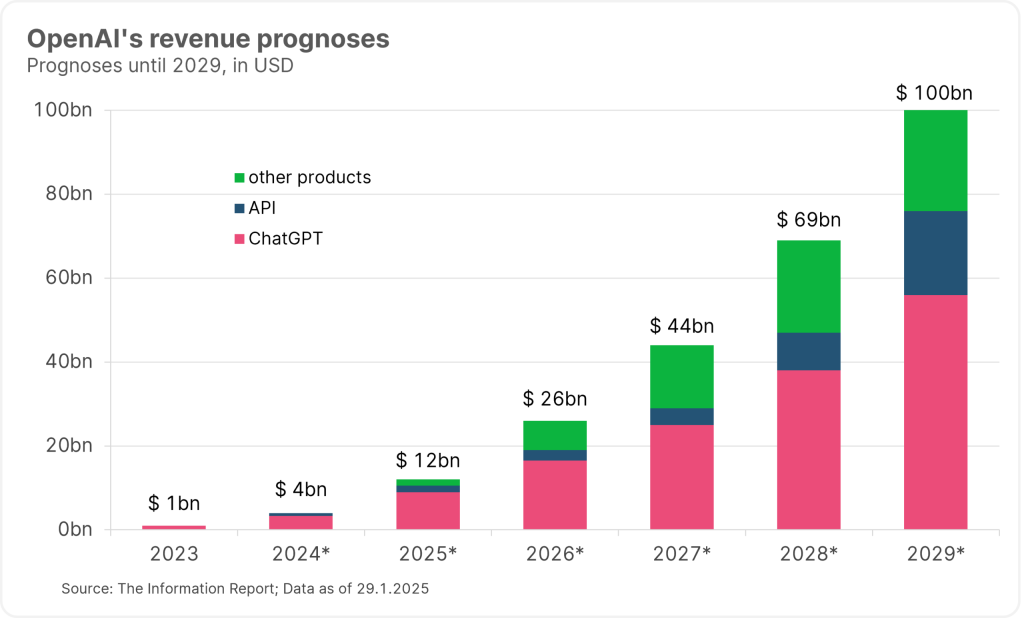
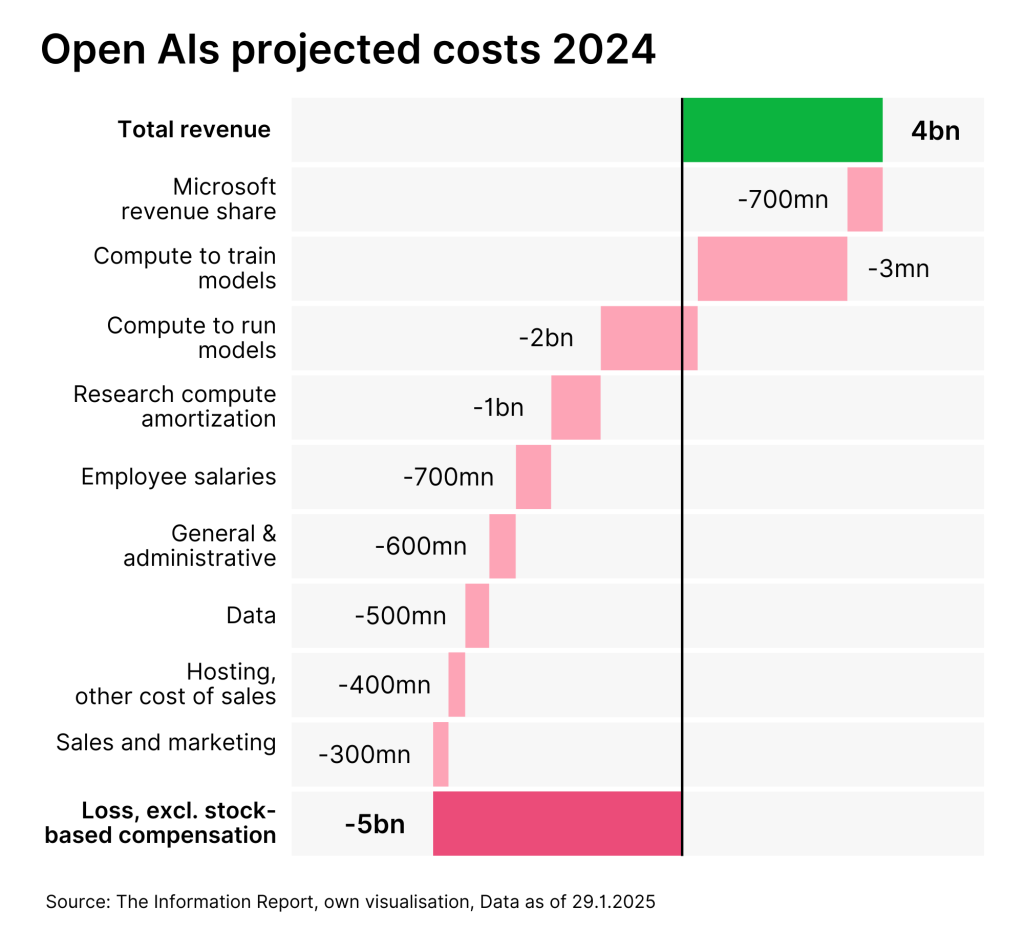
This disillusionment is doubly painful for OpenAI, the creators of ChatGPT and pioneers of the AI boom. On the one hand, the company is on its way to an IPO, where it would like to raise more than USD 100 billion in investor funds. There is now a very big question mark over these intentions. On the other hand, the company had focused its entire growth strategy on the B2C business. A large part of its turnover of around USD 4 billion in 2024 came from the subscription business. By 2029, this line of business alone was expected to grow to over USD 50 billion. In addition, OpenAI recently ventured into a new pricing scheme. The latest model, o3, will only be available to Pro users who are willing to pay USD 200 per month. This should finally stabilize the profitability of the company, which according to estimates is still making a loss of one dollar for every two dollars in revenue.
The arrival of DeepSeek must therefore be seen as an existential threat to OpenAI. It is still unclear to what extent OpenAI’s major investor Microsoft will take a hit. In any case, the company will have to question its decision to integrate the OpenAI models exclusively into the Microsoft Copilot product series.
Note: Prognoses are not a reliable indicator of future performance.
Regulation could play a decisive role
Of all things, the much-maligned regulations could become a crutch for existing closed source companies. The EU AI Act and similar regulations require far-reaching and complex audits of AI models so that they can be used commercially. A relatively small research lab like DeepSeek, which makes its product freely available anyway, will be hard to persuade to fill out pages of forms with its lawyers and send them to Brussels or Sacramento.
The US tech giants have a clear advantage here and it can only be a matter of time before voices are raised calling for greater regulation of open source models. In some cases, this is already happening anyway with reference to R1’s self-censorship as soon as it is confronted with questions about Chinese domestic politics or history. Whether it will be important to the average user that their AI assistant truthfully reports on the Tiananmen Square massacre while writing an email to their boss is another matter.
It seems inevitable that AI models will be seen as an interchangeable resource in future and not as a product per se. A market dynamic similar to the once highly acclaimed then rapidly standardized and rationalized solar panels is conceivable. On the one hand, this plays into the hands of Apple and Amazon, who have been accused of inactivity in the AI sector in recent years. Apple has set itself the goal of integrating AI models into its products in the best possible way without being drawn into a battle of resources. In hindsight, this was exactly the right strategy. With AWS Bedrock, Amazon has created the de facto industry standard for the cloud hosting of AI models, making itself independent of the success of a single model provider.
Investors will scrutinize who benefits from AI implementation
The greatest uncertainty at the moment is in the semiconductor sector, above all, of course, with the wunderkind Nvidia. As described above, there are currently many more arguments for a decline in demand for graphics processors. In relevant circles, there is currently a lot of talk about Jevon’s Paradox, which roughly states that as soon as a software service becomes cheaper, demand for it increases disproportionately and ultimately even causes the market to grow. On the other hand, however, there is still no “AI killer app”. In short, if LLMs and similar models were to disappear overnight, only a limited number of people outside AI research would probably notice.
For the vast majority of users, the use cases for AI are limited to writing homework and generating funny deep pictures, if they use the technology at all. It will therefore be all the more important for investors to check which companies can benefit from the implementation of artificial intelligence and are not in an inescapable race to the bottom.
Legal disclaimer
This document is an advertisement. Unless indicated otherwise, source: Erste Asset Management GmbH. The language of communication of the sales offices is German and the languages of communication of the Management Company also include English.
The prospectus for UCITS funds (including any amendments) is prepared and published in accordance with the provisions of the InvFG 2011 as amended. Information for Investors pursuant to § 21 AIFMG is prepared for the alternative investment funds (AIF) administered by Erste Asset Management GmbH pursuant to the provisions of the AIFMG in conjunction with the InvFG 2011.
The currently valid versions of the prospectus, the Information for Investors pursuant to § 21 AIFMG, and the key information document can be found on the website www.erste-am.com under “Mandatory publications” and can be obtained free of charge by interested investors at the offices of the Management Company and at the offices of the depositary bank. The exact date of the most recent publication of the prospectus, the languages in which the fund prospectus or the Information for Investors pursuant to Art 21 AIFMG and the key information document are available, and any other locations where the documents can be obtained are indicated on the website www.erste-am.com. A summary of the investor rights is available in German and English on the website www.erste-am.com/investor-rights and can also be obtained from the Management Company.
The Management Company can decide to suspend the provisions it has taken for the sale of unit certificates in other countries in accordance with the regulatory requirements.
Note: You are about to purchase a product that may be difficult to understand. We recommend that you read the indicated fund documents before making an investment decision. In addition to the locations listed above, you can obtain these documents free of charge at the offices of the referring Sparkassen bank and the offices of Erste Bank der oesterreichischen Sparkassen AG. You can also access these documents electronically at www.erste-am.com.
Our analyses and conclusions are general in nature and do not take into account the individual characteristics of our investors in terms of earnings, taxation, experience and knowledge, investment objective, financial position, capacity for loss, and risk tolerance. Past performance is not a reliable indicator of the future performance of a fund.
Please note: Investments in securities entail risks in addition to the opportunities presented here. The value of units and their earnings can rise and fall. Changes in exchange rates can also have a positive or negative effect on the value of an investment. For this reason, you may receive less than your originally invested amount when you redeem your units. Persons who are interested in purchasing units in investment funds are advised to read the current fund prospectus(es) and the Information for Investors pursuant to § 21 AIFMG, especially the risk notices they contain, before making an investment decision. If the fund currency is different than the investor’s home currency, changes in the relevant exchange rate can positively or negatively influence the value of the investment and the amount of the costs associated with the fund in the home currency.
We are not permitted to directly or indirectly offer, sell, transfer, or deliver this financial product to natural or legal persons whose place of residence or domicile is located in a country where this is legally prohibited. In this case, we may not provide any product information, either.
Please consult the corresponding information in the fund prospectus and the Information for Investors pursuant to § 21 AIFMG for restrictions on the sale of the fund to American or Russian citizens.
It is expressly noted that this communication does not provide any investment recommendations, but only expresses our current market assessment. Thus, this communication is not a substitute for investment advice.
This document does not represent a sales activity of the Management Company and therefore may not be construed as an offer for the purchase or sale of financial or investment instruments.
Erste Asset Management GmbH is affiliated with the Erste Bank and austrian Sparkassen banks.
Please also read the “Information about us and our securities services” published by your bank.
More on the topic

The Tariff Man
Last Sunday, the US government announced new tariffs on goods from Canada, Mexico and China, only to suspend them again shortly afterwards. How might the trade conflict develop? Is the EU also threatened with new tariffs?